4.3.1. awesome-chinese-nlp¶
![]()
A curated list of resources for NLP (Natural Language Processing) for Chinese
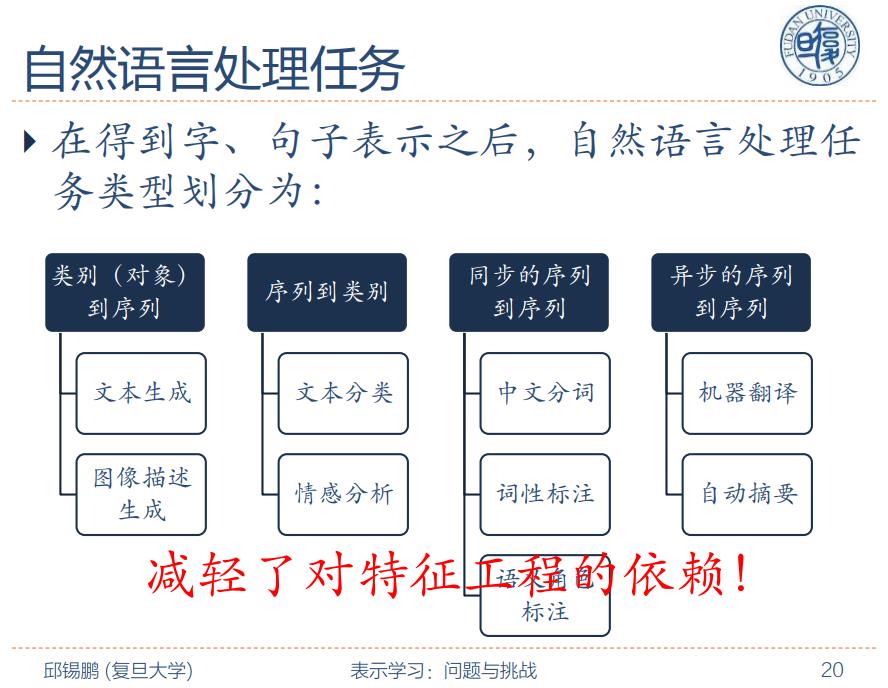
图片来自复旦大学邱锡鹏教授¶
4.3.1.1. 工具¶
4.3.1.1.1. NLP 工具包¶
THULAC 中文词法分析工具包 by 清华 (C++/Java/Python)
NLPIR by 中科院 (Java)
LTP 语言技术平台 by 哈工大 (C++) pylyp LTP 的 python 封装
FudanNLP by 复旦 (Java)
BaiduLac by 百度 Baidu’s open-source lexical analysis tool for Chinese, including word segmentation, part-of-speech tagging & named entity recognition.
HanLP (Java)
SnowNLP (Python) Python library for processing Chinese text
YaYaNLP (Python) 纯 python 编写的中文自然语言处理包,取名于“牙牙学语”
小明 NLP (Python) 轻量级中文自然语言处理工具
DeepNLP (Python) Deep Learning NLP Pipeline implemented on Tensorflow with pretrained Chinese models.
chinese_nlp (C++ & Python) Chinese Natural Language Processing tools and examples
Chinese-Annotator (Python) Annotator for Chinese Text Corpus 中文文本标注工具
Poplar (Typescript) A web-based annotation tool for natural language processing (NLP)
4.3.1.1.2. 英文或多语言 NLP 工具包¶
CoreNLP by Stanford (Java) A Java suite of core NLP tools.
NLTK (Python) Natural Language Toolkit
spaCy (Python) Industrial-Strength Natural Language Processing
textacy (Python) NLP, before and after spaCy
OpenNLP (Java) A machine learning based toolkit for the processing of natural language text.
gensim (Python) Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora.
Kashgari - Simple and powerful NLP framework, build your state-of-art model in 5 minutes for named entity recognition (NER), part-of-speech tagging (PoS) and text classification tasks. Includes BERT and word2vec embedding.
4.3.1.1.3. 中文分词¶
Jieba 结巴中文分词 (Python 及大量其它编程语言衍生) 做最好的 Python 中文分词组件
北大中文分词工具 (Python) 高准确度中文分词工具,简单易用,跟现有开源工具相比大幅提高了分词的准确率。
kcws 深度学习中文分词 (Python) BiLSTM+CRF 与 IDCNN+CRF
ID-CNN-CWS (Python) Iterated Dilated Convolutions for Chinese Word Segmentation
Genius 中文分词 (Python) Genius 是一个开源的 python 中文分词组件,采用 CRF(Conditional Random Field)条件随机场算法。
loso 中文分词 (Python)
yaha “哑哈”中文分词 (Python)
ChineseWordSegmentation (Python) Chinese word segmentation algorithm without corpus(无需语料库的中文分词)
Go 语言高性能分词 (Go) Go efficient text segmentation; support english, chinese, japanese and other.
4.3.1.1.4. 信息提取¶
MITIE (C++) library and tools for information extraction
Duckling (Haskell) Language, engine, and tooling for expressing, testing, and evaluating composable language rules on input strings.
IEPY (Python) IEPY is an open source tool for Information Extraction focused on Relation Extraction.
Snorkel A training data creation and management system focused on information extraction
Neural Relation Extraction implemented with LSTM in TensorFlow
Information-Extraction-Chinese Chinese Named Entity Recognition with IDCNN/biLSTM+CRF, and Relation Extraction with biGRU+2ATT 中文实体识别与关系提取
Familia 百度出品的 A Toolkit for Industrial Topic Modeling
Text Classification All kinds of text classificaiton models and more with deep learning. 用知乎问答语聊作为测试数据。
4.3.1.1.5. 问答和聊天机器人¶
Rasa NLU (Python) turn natural language into structured data, a Chinese fork at Rasa NLU Chi
Rasa Core (Python) machine learning based dialogue engine for conversational software
Snips NLU (Python) Snips NLU is a Python library that allows to parse sentences written in natural language and extracts structured information.
DeepPavlov (Python) An open source library for building end-to-end dialog systems and training chatbots.
ChatScript Natural Language tool/dialog manager, a rule-based chatbot engine.
Chatterbot (Python) ChatterBot is a machine learning, conversational dialog engine for creating chat bots.
Chatbot (Python) 基於向量匹配的情境式聊天機器人
Tipask (PHP) 一款开放源码的 PHP 问答系统,基于 Laravel 框架开发,容易扩展,具有强大的负载能力和稳定性。
QuestionAnsweringSystem (Java) 一个 Java 实现的人机问答系统,能够自动分析问题并给出候选答案。
QA-Snake (Python) 基于多搜索引擎和深度学习技术的自动问答
使用深度学习算法实现的中文阅读理解问答系统 (Python)
AnyQ by Baidu 主要包含面向 FAQ 集合的问答系统框架、文本语义匹配工具 SimNet。
DuReader 中文阅读理解 Baseline 代码 (Python)
基于 SmartQQ 的自动机器人框架 (Python)
QASystemOnMedicalKG (Python) 以疾病为中心的一定规模医药领域知识图谱,并以该知识图谱完成自动问答与分析服务。
4.3.1.2. 中文语料¶
农业知识图谱 农业领域的信息检索,命名实体识别,关系抽取,分类树构建,数据挖掘
[搜狗 20061127 新闻语料(包含分类)@百度盘](https://pan.baidu.com/s/1bnhXX6Z)
UDChinese (for training spaCy POS)
Tencent AI Lab Embedding Corpus for Chinese Words and Phrases
中华新华字典数据库 包括歇后语,成语,词语,汉字。
Synonyms:中文近义词工具包 基于维基百科中文和 word2vec 训练的近义词库,封装为 python 包文件。
Chinese_conversation_sentiment A Chinese sentiment dataset may be useful for sentiment analysis.
中文突发事件语料库 Chinese Emergency Corpus
dgk_lost_conv 中文对白语料 chinese conversation corpus
用于训练中英文对话系统的语料库 Datasets for Training Chatbot System
中国股市公告信息爬取 通过 python 脚本从巨潮网络的服务器获取中国股市(sz,sh)的公告(上市公司和监管机构)
tushare 财经数据接口 TuShare 是一个免费、开源的 python 财经数据接口包。
保险行业语料库 [52nlp 介绍 Blog] OpenData in insurance area for Machine Learning Tasks
最全中华古诗词数据库 唐宋两朝近一万四千古诗人, 接近 5.5 万首唐诗加 26 万宋诗. 两宋时期 1564 位词人,21050 首词。
中文语料小数据 包含了中文命名实体识别、中文关系识别、中文阅读理解等一些小量数据
大规模中文自然语言处理语料 维基百科(wiki2019zh),新闻语料(news2016zh),百科问答(baike2018qa)
中文人名语料库 中文姓名,姓氏,名字,称呼,日本人名,翻译人名,英文人名。
中文敏感词词库 敏感词过滤的几种实现+某 1w 词敏感词库
中文简称词库 A corpus of Chinese abbreviation, including negative full forms.
中文数据预处理材料 中文分词词典和中文停用词
SentiBridge: 中文实体情感知识库 刻画人们如何描述某个实体,包含新闻、旅游、餐饮,共计 30 万对。
OpenCorpus A collection of freely available (Chinese) corpora.
ChineseNlpCorpus 情感/观点/评论 倾向性分析,中文命名实体识别,推荐系统
4.3.1.3. 中文 NLP 学术组织及竞赛¶
NLP Conference Calender Main conferences, journals, workshops and shared tasks in NLP community.
2017 AI-Challenger 图像中文描述 用一句话描述给定图像中的主要信息,挑战中文语境下的图像理解问题。
2017 AI-Challenger 英中机器文本翻译 用大规模的数据,提升英中文本机器翻译模型的能力。
2017 知乎看山杯机器学习挑战赛 根据知乎给出的问题及话题标签的绑定关系的训练数据,训练出对未标注数据自动标注的模型。
2018 开放领域的中文问答任务 对于给定的一句中文问题,问答系统从给定知识库中选择若干实体或属性值作为该问题的答案。
2018 微众银行智能客服问句匹配大赛 针对中文的真实客服语料,进行问句意图匹配;给定两个语句,判定两者意图是否相近。
4.3.1.4. 中文 NLP 商业服务¶
4.3.1.5. 学习资料¶
Stanford CS224n Natural Language Processing with Deep Learning 2017
Course materials for Georgia Tech CS 4650 and 7650, “Natural Language”
Speech and Language Processing by Dan Jurafsky and James H. Martin
文本处理实践课资料 文本处理实践课资料,包含文本特征提取(TF-IDF),文本分类,文本聚类,word2vec 训练词向量及同义词词林中文词语相似度计算、文档自动摘要,信息抽取,情感分析与观点挖掘等实验。
nlp_tasks Natural Language Processing Tasks and Selected References