3.5. MMSEG¶
本文翻译自作者蔡志浩的论文: http://technology.chtsai.org/mmseg/
MMSEG: 基于两种最大匹配算法的普通话文本识别系统
发布时间: 1996-04-29
更新时间: 1998-03-06
文件已更新: 2000-03-12
证书: 免费用于非商业用途
Copyright © 1996-2006 Chih-Hao Tsai (Email: hao520@yahoo.com)
3.5.1. 什么是新的?¶
2000-03-12: 我在一个可能更有用的程序中重新分析并重新实现了 MMSEG 中使用的算法:中文词法扫描程序。 有关详细信息,请访问以下页面:CScanner -中文词汇扫描仪
3.5.2. 抽象¶
中文文本的计算分析存在的问题是常规打印文本中没有单词边界。 由于这个词是一个基本的语言单位,因此有必要识别中文文本中的单词,以便进行更高级别的分析。 本研究的目的是开发一种基于最大匹配算法的两种变体的单词识别系统。 该系统由词典,两个匹配算法和四个模糊度解析规则组成。 结果发现,该系统成功识别出包含 1013 个单词的样本中 98.41%的单词。 本文还将讨论该系统的潜在应用。
3.5.3. 介绍¶
Hung 和 Tzeng(1981)和 DeFrancis(1984)指出,中文书写系统在语素和音节层面上映射到口语。 结果,字符在书面中文中是不同的。 另一方面,常规印刷和书面中文文本中不存在单词边界。

Chinese example¶
3.5.3.1. 词识别过程中的困难¶
由于这个词是一个基本的语言单位,因此有必要识别中文文本中的单词,以便进行中文文本的计算分析和处理。 由于该词是基本语言单元,因此有必要识别中文文本中的单词,以进行计算分析和处理中文文本。

Chinese example¶
首先,几乎所有角色本身都可以是单字符。 而且,他们可以加入其他角色来形成多角色词。 这导致大量的分割模糊。 其次,复合是现代汉语中主要的词汇形成手段。 通常很难判断低频化合物是单词还是短语,而词典永远无法彻底收集所有低频化合物。 第三,相同的字符池也用于构造专有名称。 识别专有名称也是一个问题。 最后,还需要考虑一些特定的形态结构,如重复和 A-not-A 结构。
除了少数例外(例如 Huang,Ahrens,&Chen,1993; Sproat 和 Shih,1990),大多数单词识别方法都有一个共同的算法:匹配(例如,Chen 和 Liu,1992; Fan&Tsai,1988; Yeh&李,1991)。 基本策略是将输入字符串与存储在预编译词典中的大量条目进行匹配,以查找所有(或部分)可能的分段。 由于通常只有一个正确的分割,因此需要解决歧义。
3.5.3.2. 最大匹配算法及其变种¶
不同的研究在模糊度分辨率算法上有所不同。 已经证明非常有效的一个非常简单的是最大匹配算法(Chen 和 Liu,1992)。 最大匹配可以采用多种形式。
简单的最大匹配。 基本形式是解决单个词的含糊不清(李一如,个人通讯,1995 年 1 月 14 日)。 例如,假设 C1,C2,…… Cn 表示字符串中的字符。 我们在字符串的开头,想知道单词的位置。 我们首先搜索词典以查看C1是否是一个单字符的单词,然后搜索C1C2以查看它是否是一个双字符的单词,依此类推,直到该组合长于词典中最长的单词。 最合理的词将是最长的匹配。 我们接受这个词,然后继续这个过程,直到识别出字符串的最后一个字。
复杂的最大匹配。 Chen 和 Liu(1992)所做的最大匹配的另一种变体比基本形式更复杂。 他们的最大匹配规则表明,最合理的分割是具有最大长度的三字组块。 同样,我们处于字符串的开头,想要知道单词的位置。 如果存在不明确的分段(例如,C1是一个字,但C1C2也是一个字,依此类推),那么我们再向前看两个字以找到以C1或C1C2开头的所有可能的三字组块。 例如,如果这些是可能的三字组块:
1. _C1_ _C2_ _C3C4_
2. _C1C2_ _C3C4_ _C5_
3. _C1C2_ _C3C4_ _C5C6_
Chinese example¶
最大长度的块是第三个。 第三个字块的第一个字C1C2将被视为正确的字。 我们接受这个词,继续从字符 C3 重复这个过程,直到识别出字符串的最后一个字。 陈和刘(1992)报告说,这条规则达到了 99.69%的准确率,93.21%的歧义通过这条规则得到了解决。
3.5.3.3. 其他消歧算法¶
除了最大匹配之外,还提出了许多其他消歧算法。 在消除歧义的过程中使用各种信息。 例如,概率和统计(Chen 和 Liu,1992; Fan&Tsai,1988),语法(Yeh&Lee,1991)和形态学(Chen 和 Liu,1992)。 它们中的大多数需要具有良好构造的词典,其具有诸如字符和单词频率,单词的句法类别以及一组语法或形态规则的信息(例如,中文知识信息处理组[CKIP],1993a,1993b,1993c)。
3.5.4. MMSEG 系统概述¶
MMSEG 系统实现了前面讨论的最大匹配算法的简单和复杂形式。 此外,为了解决复杂的最大匹配算法未解决的模糊性,已经实现了另外三个模糊度解析规则。
其中一个由 Chen 和 Liu(1992)提出,其余两个是新的。 这些规则将在稍后讨论。 该系统没有特殊的规则来处理专有名称和特定的形态结构,如重复和 A-not-A 结构。
必须指出的是,MMSEG 并非设计为“专业级”系统,其目标是 100%正确识别。 相反,应将 MMSEG 视为可以测试新的模糊度解析算法的通用平台。 然而,我们将看到即使是当前版本的 MMSEG 也达到了很高的准确率,这与学术期刊上发布的一致。
3.5.4.1. 词典¶
词典的第一部分包括 124,499 个多字符条目。 词条的长度从两个字符到八个字符不等。 有关字长的分布,请参见附录 A. 词典很简单,是一个有组织的字符串列表。 没有与每个字符串相关的其他信息。 词典的基础是作者保留的 137,450 个中文单词列表(Tsai,1996c)。 反过来,这个列表是通过合并互联网上可访问的几个中文单词列表创建的(Tsai,1996a)。
词典的第二部分包括 13,060 个字符及其使用频率(Tsai,1996b)。 字符频率用于最后的模糊度解析规则。
3.5.4.2. 匹配算法¶
简单: 对于字符串中的字符 Cn,将以 Cn 开头的子字符串与词典匹配,并查找所有可能的匹配项。
复杂: 对于字符串中的字符 Cn,找到以 Cn 开头的所有可能的三字块,无论第一个字是否有任何歧义。 只有在第一个单词含糊不清时才会形成三个字的块。
3.5.4.3. 歧义解决规则¶
使用了四个模糊度解析规则。 最大匹配规则应用于简单和复杂匹配算法的模糊分段。 其余三个规则没有(也不能)应用于简单匹配算法的模糊分割。
3.5.4.3.1. 规则 1:最大匹配¶
(Chen 和 Liu 1992)。
简单的最大匹配:选择具有最大长度的单词。
复杂的最大匹配:从最大长度的块中选择第一个单词。如果有多个具有最大长度的块,请应用下一个规则。
3.5.4.3.2. 规则 2:最大平均字长¶
(Chen&Liu,1992)。
在每个字符串的末尾,很可能只有一个或两个单词的块。 例如,以下块具有相同的长度和相同的字长方差。
1. _C1_ _C2_ _C3_
2. _C1C2C3_

Chinese example¶
规则 2 从具有最大平均字长的块中选择第一个单词。 在上面的例子中,它从第二个块中选择C1C2C3。 这个规则的假设是它更可能遇到多字符单词而不是单字符单词。
此规则仅适用于块中的一个或多个单词位置为空的条件。 当块是真正的三字块时,此规则无用。 因为具有相同总长度的三字块肯定具有相同的平均长度。 因此,我们需要另一种解决
3.5.4.3.3. 规则 3:字长的最小变化¶
(Chen 和 Liu,1992)。
规则 1 和规则 2 无法解决相当多的模糊条件。 例如,这两个块具有相同的长度:
1. _C1C2_ _C3C4_ _C5C6_
2. _C1C2C3_ _C4_ _C5C6_
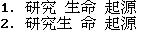
Chinese example¶
规则 3 选择具有最小字长方差的块的第一个。 在上面的例子中,它从第一个块中选择C1C2。 这条规则与 Chen 和 Liu(1992)提出的规则完全相同(但是,它们在规则 1 之后立即应用了这条规则。) 这个规则的假设是字长通常是均匀分布的。 如果有多个块具有相同的字长方差值,则应用下一个规则。
3.5.4.3.4. 规则 4:单字词的语素自由度的最大总和。¶
此示例显示了两个具有相同长度,方差和平均字长的块:
1. _C1_ _C2_ _C3C4_
2. _C1_ _C2C3_ _C4_

Chinese example¶
两个块都有两个单字符和一个双字字。 哪一个更可能是正确的?在这里,我们将关注单字词。 汉字在语素自由度上有所不同。 有些字符很少用作自由语素,但其他字符具有较大的自由度。 角色的出现频率可以作为其语素自由度的指标。 高频字符更可能是单字符字,反之亦然。
用于计算语素自由度之和的公式是对一个块中所有单字符字的对数(频率)求和。 对数变换的基本原理是相同数量的频率差异在所有频率范围内不具有一致的效果。
规则 4 比选择具有最大 log(频率)总和的块的第一个单词。 由于两个字符不太可能具有完全相同的频率值,因此在应用此规则后应该没有歧义。
3.5.4.4. 执行¶
MMSEG 系统是用 C 编程语言编写的。
硬件和软件环境。 MMSEG 在 IBM 兼容 PC(486DX-33)上运行,主内存为 1 MB,扩展内存为 12 MB。 操作系统是 MS-DOS。 用于构建 MMSEG 的编译器是 Turbo C ++ 3.0。 包括可执行文件,源代码,词典,索引和测试数据,整个 MMSEG 系统占用了大约 1.5 MB 的磁盘空间。
3.5.4.4.1. 结果¶
由 1013 个单词组成的测试样本用于测试 MMSEG 的两组单词识别算法。 表 1 显示了初步测试结果。
表 1 测试结果
识别简单 |
算法复杂 |
|
|---|---|---|
识别的单词(N2) |
1012 |
1010 |
正确识别(N3) |
966 |
994 |
召回率(N3 / N1) |
95.36% |
98.12% |
精度(N3 / N2) |
95.45% |
98.41% |
!!! note “”
注意:输入样本中的字数(N1)是 1013。
毫不奇怪,即使简单的最大匹配算法也能正确识别测试样本中超过 95%的单词。 这可以被视为评估单词识别算法的基线。
具有四个模糊度解析规则的复杂匹配算法,正确识别测试样本中超过 98%的单词。 性能优于简单匹配算法。
表 2 显示了每个模糊度解析规则的成功率。 前两个规则解决了总模糊实例的 90%,并且成功率相对较高。 规则 1 解决了大多数(59.5%)的歧义。 规则 2 解决了 30.6%。 规则 3 仅解决了总模糊度的 1%,规则 4 解决了 9%。 这些规则的准确性一般相对较高,但规则 3 的准确性略低于其他规则。
表 2 每个模糊度解析规则的准确性
歧义解决规则 |
1 |
2 |
3 |
4 |
|---|---|---|---|---|
标识 |
400 |
245 |
6 |
82 |
错误 |
5 |
4 |
2 |
4 |
准确性 |
98.75% |
98.37% |
66.67% |
95.12% |
!!! note “”
- 规则 1 =最大匹配。
- 规则 2 =最大平均字长。
- 规则 3 =字长的最小方差。
- 规则 4 =单字词的语素自由度的最大和。
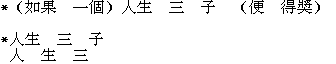

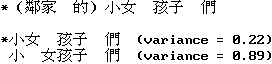

3.5.5. 讨论¶
MMSEG 系统的准确性与学术期刊上发布的准确性一样高。 这一发现表明 MMSEG 是一个成功的中文单词识别系统。
已经证明四个模糊度解析规则非常有效。 规则 1(最大匹配)解决了大多数歧义。 具体而言,规则 3(最大平均字长)解决了比我预期更多的模糊性。而且它非常准确。 对数据的检查表明,正如预期的那样,规则 3 解决的大多数歧义都是句末歧义。 令人惊讶的是,规则 2 解决了很少的歧义(字长的最小方差)。 这可能与每个规则的顺序有关。 在早期版本的 MMSEG 中,规则 3 在规则 2 之前适用。 在该版本中,规则 2 解决了比当前 MMSEG 更多的模糊性。 规则 4(单字词的语素自由度的最大总和)表现得相当好。 这表明统计信息在消歧中很有用。
如前所述,MMSEG 被设计成一个通用平台,可以在其上测试新的模糊度解析算法。 我将来想做的是提出关于中国读者在阅读过程中如何识别单词和单词边界的假设。 然后我可以使用 MMSEG 来测试这些算法。 与此同时,我还将设计实验来收集人类受试者的数据。 通过比较计算机程序和人类受试者的表现,我可以(希望)确定每种算法的心理现实。
3.5.6. 可用性和可移植性¶
MMSEG 的源代码和可执行文件以 zip 存档的形式提供。 点击下面的链接下载:
mmseg.zip (532KB)
mmseg 的源代码可以使用 gcc 编译而无需修改,因此它基本上与平台无关。
我们鼓励您将 MMSEG 用于研究目的。 我们也鼓励您使用 MMSEG 开发免费软件,只要您在源代码和文档中适当地承认我和 MMSEG 并向我发送您的软件副本。 但是,MMSEG 的任何商业用途都需要个人许可。
3.5.7. MMSEG,Libtabe 和 XCIN¶
Libtabe 是由 [Pai-Hsiang Hsiao] shawn@iis.sinica.edu.tw 领导的 TaBE 项目发布的 C 库。 Libtabe 提供统一的界面和支持功能,用于处理汉字,声音,单词和句子。
MMSEG 使用的一组字识别算法由 Pai-Hsiang Hsiao 在最新版本的 libtabe 中实现,以提供字识别功能。 凭借 libtabe 的这种能力,Pai-Hsiang Hsiao 能够开发出一个名为 bims 的模块,它可以非常精确地从一串普通话音节中智能地恢复正确的字符。 众所周知,同音字在汉字中很常见。 在这种情况下,Libtabe 的成就非常重要。
最新版本的 XCIN 是一种 XIM(X 输入法)服务器,广泛用于 X Window 系统,提供中文输入功能,现在与 libtabe 集成,提供智能语音输入模块。 事实证明,这个模块和商业产品一样好。
3.5.8. 参考¶
Chen,K.J。,Liu,S.H。(1992)。汉语句子的语言识别。 第 15 届南特计算语言学国际会议论文集:COLING-92。
中国知识信息处理集团(1993a)。 基于语料库的中文期刊人物频率统计(CKIP 技术报告第 93-01 号)。台湾台北:中央研究院。
中国知识信息处理小组。(1993b)。 基于语料库的中文期刊词汇频率统计(CKIP 技术报告 No.93-02)。台湾台北:中央研究院。
中国知识信息处理小组。(1993c)。 Mandaring Chinese 的 CKIP 分类分类(CKIP 技术报告 No.93-05)。台湾台北:中央研究院。
DeFrancis,J。(1984)。中文:事实与幻想。檀香山,HI:夏威夷大学出版社。
Fan,C.K。,&Tsai,W.H。(1988)。通过松弛技术在汉语句子中进行自动单词识别。 中国和东方语言的计算机处理,4,33-56。
Huang,C.R.,Ahrens,K。和 K.J.Chen。(1993 年 12 月)。心理词汇心理现实的数据驱动方法:中国语料库语言学的两项研究。 论文在台湾台北举行的语言生物学和心理学基础国际会议上发表。
Hung,D.L,&Tzeng,O。(1981)。正交变异和视觉信息处理。 心理学通报,90,377-414。
Sproat,R。,&Shih,C。(1990)。一种在中文文本中查找单词边界的统计方法。 中国和东方语言的计算机处理,4,336-351。
Tsai,C.H。(1996a)。可在互联网上查看中文单词列表。
Tsai,C.H。(1996b)。汉字的频率和笔画数。
Tsai,C.H。(1996c)。蔡的中文单词列表。
Yeh,C.L。,&Lee,H.J。(1991)。基于规则的汉语句子词识别 - 一种统一的方法。 中国和东方语言的计算机处理,5,97-118。
3.5.9. 安装和执行 MMSEG¶
MMSEG 的当前实现不会将词典加载到计算机存储器中。 它只将索引加载到内存中并在硬盘上搜索词典。 因此,建议安装快速硬盘并安装磁盘缓存磁盘缓存。 而快速的奔腾 PC 始终是首选。
要安装,请将 mmseg.zip 解压缩到任何文件夹。
执行 mmseg:
MMSEG file1 file1 path [complexity][progress note]
file1: source file to be processed
file2: target file to write segmented text to
path: where the lexicon can be found
complexity: Complexity of matching algorithm:
simple Simple (1 word) matching (default)
complex Complex (3-word chunk) matching
progress note (for complex matching only): Progress note sent to
standard output (screen) during segmentation:
verbose Display (1) All ambiguous segmentations and the
length, variance of word lengths, average word length, and sum
of log(frequency) for each each segmentation (2) Number of
ambiguous segmentations not resolved by each disambiguation
rule, and at which rule the ambiguity is resolved
standard Display (2) only
quiet None of the above information will be displayed
Example: MMSEG in.txt out.txt .\lexicon\ complex quiet
3.5.10. 作者说明¶
本文结合了伊利诺伊大学厄巴纳 - 香槟分校的 Chin-Chuan Cheng 教授的“计算语言学专题”和“中国语言学研讨会”两个学期项目。 1995 年,当我提出编写中文单词识别程序的想法时,我对计算语言学知之甚少。 凭借我在过去两个学期的课程中获得的知识,我现在能够实施这样一个系统。
我还要感谢伊利诺伊大学的 George McConkie 教授,台湾中央研究院的 Chu-Ren Huang 教授,AT&T 贝尔实验室的 Richard Sproat 教授以及 Cheng Cheng 的计算机科学研究生李一如 - 台湾功夫大学提出的富有洞察力的建议。
我还要感谢伊利诺伊大学的 George McConkie 教授,台湾中央研究院的 Chu-Ren Huang 教授,AT&T 贝尔实验室的 Richard Sproat 教授以及 Cheng Cheng 的计算机科学研究生李一如 - 台湾功夫大学提出的富有洞察力的建议。
3.5.11. 链接¶
ROCLING(计算语言学与中文语言处理协会), Taiwan
中国知识信息处理小组, 信息科学研究所, 中央研究院, Taiwan
在线语料库搜索服务, 信息科学研究所, 中央研究院, Taiwan
郭进的研究论文与休闲着作, 郭进,新加坡国立大学系统科学研究所
中国的 PH 语料库, 郭进,新加坡国立大学系统科学研究所
中国 Usenet 档案(FTP), 台湾国立交通大学计算机科学与信息工程系
Chang,C.H。(1994)。关于自动汉语拼写纠错的初步研究,COLIPS 通讯,4(2),143-149。
Chang,C.H。(1995 年 12 月)。一种新的自动汉语拼写校正方法,“自然语言处理论文集”95(NLPRS’95)(第 272-283 页),韩国首尔[最佳论文获奖者之一]